|
新西兰学术实验报告-How the depth of processing influence memory
Table of contents目录
Abstract 3摘要
1.0 Introduction 4引言
2.0 Method 6方法
2.1 Design 6设计
2.2 Participants 6参与者
2.3 Materials 6材料
2.4 Procedures 7程序
3.0 Results 8结果
4.0 Discussion 10讨论
4.1 t Value 10t值
4.2 Degree of freedom 11自由度
4.3 P Value 12p值
References 14参考文献
Abstract摘要
记忆是研究过程中的一个共同课题。另外,在本研究中,作者希望应用配对样本t检验来调整记忆的处理。在本研究中,充分运用了三个关键值:t值、自由度和p值,使这三个值最终能够界定记忆的关系。
Memory is a common topic in the process of the research. In addition, in the research, the author would like to apply the paired sample t-test to adjust the processing of the memory. In this research, the three key values are fully applied: t-value, the degree of the freedom and p-value, so that these three values could defined the finally to prove the relationship for the memories.
1.0 Introduction简介
记忆是人类对记忆事物,保持,重现或认识的认识。它是开展思想,想象力和其他高级心理活动。人体记忆和海马的大脑结构,使大脑的化学成分发生变化。记忆作为一种基本的心理过程,与其他心理活动密切相关。记忆与人们的心理活动联系起来(Dutriaux&Gyselinck,2016)。记忆是人们学习,工作和生活的基本功能。抽象障碍进入图像秩序的过程是记忆的关键。记忆的研究属于心理学或脑科学的范畴。现代人类记忆研究仍在继续,尽管今天的科学和技术已经突飞猛进。练习后的使用可以有效地提高方法,技能的记忆力,可以更好地服务于人类的工作,日常生活和学习(vonStülpnagel,Steffens,&Schult,2016)。
Memory is the recognition of the human mind to remember things, keeping, reproduce or recognize. It is to carry out thinking, imagination and other high-level psychological activities. Human memory and brain structure of the hippocampus, the brain changes in the chemical composition.Memory as a basic psychological process, and other psychological activities are closely linked. Memory links with people's mental activities (Dutriaux&Gyselinck, 2016). Memory is the basic function of people learning, working and living. The process of abstract disorder into image order is the key of memory.The study of memory belongs to the category of psychology or brain science. Modern human memory research continues, although today's science and technology has been developed by leaps and bounds. The use of those after practice can effectively improve the memory of the methods, skills, can make it better serve the human work, dailylife, and learning (von Stülpnagel, Steffens, &Schult, 2016).
While learning is seen as an obvious part of schooling, this makes it a process of concealment and teacher observation, re-instruction, or immediate corrective inaccessibility. An important aspect of learning that is often taken for granted is that learners are successfully involved in multiple messages simultaneously, following multiple step directions, solving problems, or through a lesson or teaching objectives such as self-managing implicit needs such as complex thinking, e.g., tracking of the accumulation over an extended period of time (Moreira, et al., 2015). However, this seemingly basic ability is complex and involves well-coordinated cognitive processes between at least three administrative functions: inhibitory control, working memory renewal, and mental transfer The typical characteristic of working memory capacity is that the information individual can Processing the same time to perform complex tasks.
虽然学习被视为学校教育的一个明显部分,但这使得它成为一个隐藏和教师观察,重新指导或立即纠正不可访问的过程。经常被视为理所当然的学习的一个重要方面是学习者同时成功地参与多个信息,遵循多个步骤指导,解决问题,或通过课程或教学目标,例如自我管理隐含需求,例如复杂思维,例如,追踪长期积累(Moreira,et al。,2015)。然而,这种看似基本的能力是复杂的,涉及至少三个行政职能之间协调良好的认知过程:抑制控制,工作记忆更新和心理转移工作记忆容量的典型特征是个人可以同时处理的信息。执行复杂的任务。Normally working memory capacity is characterized as being within the range of information that the individual can process at the same time to perform complex tasks. The larger a person's capacities, the more powerful the attention can be controlled to effectively manipulate the information and avoid processing disturbances. This psychological multitasking is achieved by the parallel processing of short-term memory from a person's attention from the highly activated long-term memory access or temporal information coordination and timely control appearing (Antoniou, Ettlinger, & Wong, 2016). In this way, it can be processed according to need, like a mental spotlight selectively according to the relevant information from one moment to another working memory function, actively do the relevant material original intention. The ineffective operation of this working memory spotlight increases the risk that distracting information will be allowed to dispose of irrelevant information, the ability to overload this information is limited, and obstructing effective spotlighting can lead to forgotten ways of shifting the mindset.
2.0 Method
2.1 Design
In the process of the research of the processing of the memory, the paired sample t-test method is applied. In addition, the definition of the paired sample t-test can be summarized as follow:
The paired sample t-test was used to compare the two demographic techniques in the case of the relevant two samples, the device. The paired sample t test is used in the "anterior - posterior" study, or when the sample was matched, or when it was a case - control study. In addition, the paired t test is similar to the repeated measurement ANOVA test. In addition, it can be used to compare the performance of static groups under different test conditions. The difference is that paired t-tests are used when the independent variable has two levels. Repeat measures ANOVA when independent variables have more than two levels used. Thus, for example, if a researcher tests three conditions, the appropriate test will be repeated for ANOVA, not a paired t-test. In addition, values are reported: t price, degree of freedom and P value (NikoueiMahani, 2016).
2.2 Participants
There are three hundred and seventy-nine participantstaking part in the study. They are supposed cover genders, ages, races and all other personal marks as much as possible. Though due to the location of this questionnaire is taken place, and the number of participants is comparatively low, the participants can be only comparatively scientific.
2.3 Materials
The random sample would like to link to memory students and also refer to the academic journals to reference to the study.
2.4 Procedures
In the process of the research, the paired samples t-test is used to the comparing deep VS shallow levels of processing.Three hundred and seventy-nine participants are randomly selected. They are supposed cover genders, ages, races and all other personal marks as much as possible. In this process, they are given to a paper of list of questions. In order to avoid environmental influences and personal and subjective bias, the participants are required to finish the questions independently.When the questions are finished, the paper is collected immediately.
3.0 Results
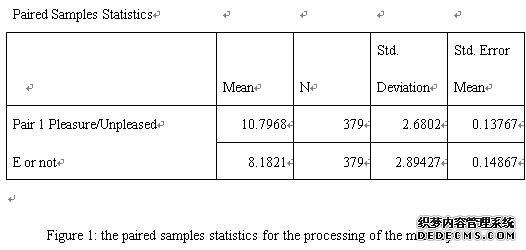 
As can be seen in the Figure 1, the mean is 10.8 and standard deviation is 7.68 for the category of the “pleasant” and also mean is 8.18 and standard deviation is 2.89 for the category of “unpleased”.
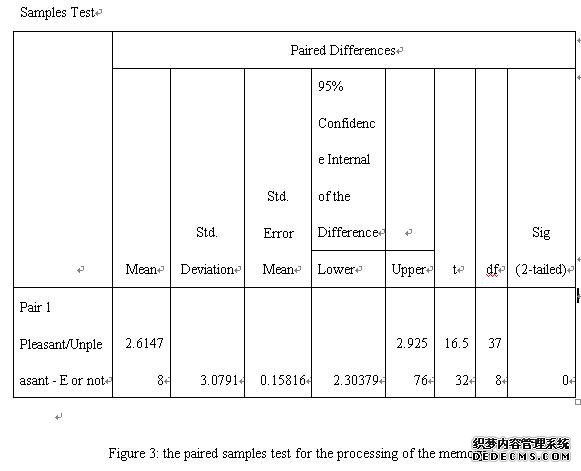
Besides that, the Figure 3 has demonstrated that the table has indicated that T-Value(t) is 16.53. In addition, the p-value (p) is less than 0.001. Also, the degree of freedom(df) is 378.
4.0 Discussion
4.1 t Value
A typical example of a repeated measurement t-test is where the subject is a prior therapeutic trial, said that for hypertension and the same subject is tested again with a hypotensive drug treatment. By comparing the same patient numbers before and after treatment, we effectively used each patient as their own control. In this way, the right to reject the null hypothesis (which is not dealt with here, the difference) can become easier; there is statistical power to simply increase, because random changes in patients have now been eliminated (Randall&Tyldesley, 2016). Note, however, that the growth of statistical power comes at a cost: more testing needs to be done twice a topic. Since half of the sample is now dependent on the other half, the student t-test pair version has a unique "n / 2-1" degree of freedom (n is the total number of observations). The pair becomes a separate test cell and the sample must be doubled to achieve the same number of degrees of freedom (Greengard, 2016).#p#分页标题#e#
The results from a paired sample are then used to form a paired sample, using other variables along the variable being measured along with the paired sample t-test "match-to-sample". Matching is performed by identifying pairs of observations from one of each two samples, with similar values for the other measurement variables. This approach is observed in studies that are sometimes used to reduce or eliminate the effects of interfering factors. Paired samples t tests are often referred to as "dependent t-tests."
As summarized, T-Value (t) is 16.53.
4.2 Degree of freedom
In statistics, the degree of freedom refers to the calculation of a statistic, the value of the number of unrestricted variables. Usually df = n-k. Where n is the number of samples, k is the number of condition numbers or variables, or the number of other independent statistics used to calculate a certain statistic. Degrees of freedom are typically used in sampling distributions (Wang & Liu, 2016). Firstly, when estimating the population mean, the number of samples in the n are independent of each other, from which any number does not affect the other data, so the degree of freedom is n. Secondly, the degree of freedom of the statistical model is equal to the number of independent variables can be free. As in the regression equation, if there are a total of p parameters need to estimate, which includes the p-1 independent variables (with the intercept of the independent variable is constant 1). Thus the degree of freedom of the regression equation is p-1. (Smith, Sáez, &Doabler, 2016). Mathematically, the degree of freedom is a dimension of a random vector, or the number of domains that are essentially "free" components (the number of components required for a pre-vector to be fully known). Degrees of freedom are also commonly used in related statistical testing problems, where the squared length, or "square sum" of the coordinates, is related to the chi-squared parameters and other distributions.
As discussed above, the degree of the freedom is 378.
4.3 P Value
In frequency statistics, the p-value is relative to a statistical model, and its measurement observes how extremes are observed in the results of the sample's function (test statistic). They have abused controversial issues. The p-value is defined as the probability that the obtained result is equal to or greater than what is actually observed when the null hypothesis is true "more extreme". In frequency theory reasoning, p-values are widely used in statistical hypothesis testing, especially in the null hypothesis test of significance. In this method, for the part of the experimental design, a first choice of a model (null hypothesis) and a threshold for p is called the significance level of the experiment before performing the experiment, traditionally 5% or 1 %, And is expressed as α. If the p-value is less than or equal to the selected significance level (α), the test indicates that the observed data is not consistent with the null hypothesis, so the null hypothesis must be rejected. However, this does not justify the hypothesis tested. When the p-value is calculated correctly, the test guarantees a class error rate of at most [alpha]. A typical analysis using the standard α = 0.05 cutoff, when p <0.05, rather than reject when p> 0.05 null hypothesis was rejected. The p-value itself does not support hypothetical probabilistic reasoning, but only applies to tools that decide whether to reject the null hypothesis. The US Statistical Association, in its statement using the p-value, affirmed the usefulness of correctly interpreting the p-value, but cautioned that the p-value was generally misused and misinterpreted (Kreinovich&Servin, 2015). Using bright-line rules as truncation, such as for ≤ 0.05, no other supporting statistics The evidence, which is particularly criticized: commonly interpreted as "P ≤ 0.05". Although it is generally accepted that p values are often misused, there is no consensus on alternatives.
As discussion above, the p-value is less than 0.001, so that the difference could be apparent.
References
1. Greengard, S. (2016). Better Memory. Communications Of The ACM, 59(1), 23-25. doi:10.1145/2843555
2. Smith, J. j., Sáez, L., &Doabler, C. T. (2016). Using Explicit and Systematic Instruction to Support Working Memory. Teaching Exceptional Children, 48(6), 275-281. doi:10.1177/0040059916650633
3. NikoueiMahani, M., Haghgoo, H. A., Azizi, S., &NiliAhmadabadi, M. (2016). Attention Cueing and Activity Equally Reduce False Alarm Rate in Visual-Auditory Associative Learning through Improving Memory. Plos ONE, 11(6), 1-14. doi:10.1371/journal.pone.0157680
4. vonStülpnagel, R., Steffens, M. C., &Schult, J. C. (2016). Memory for Five Novel Naturalistic Activities: No Memory Recall Advantage for Enactment over Observation or Pictorial Learning. Journal Of Articles In Support Of The Null Hypothesis, 12(2), 9-20.
5. Antoniou, M., Ettlinger, M., & Wong, P. M. (2016). Complexity, Training Paradigm Design, and the Contribution of Memory Subsystems to Grammar Learning. Plos ONE, 11(7), 1-20. doi:10.1371/journal.pone.0158812
6. Moreira, P. S., Almeida, P. R., Leite-Almeida, H., Sousa, N., & Costa, P. (2016). Impact of Chronic Stress Protocols in Learning and Memory in Rodents: Systematic Review and Meta-Analysis. Plos ONE, 11(9), 1-24. doi:10.1371/journal.pone.0163245
7. Dutriaux, L., &Gyselinck, V. (2016). Learning Is Better with the Hands Free: The Role of Posture in the Memory of Manipulable Objects. Plos ONE,11(7), 1-11. doi:10.1371/journal.pone.0159108
8. Randall, L., &Tyldesley, K. l. (2016). Evaluating the impact of working memory trainingprogrammes on children - a systematic review. Educational & Child Psychology, 33(1), 34-50.
9. Zhang, Y., Moore, D. R., Guiraud, J., Molloy, K., Yan, T., &Amitay, S. (2016). Auditory Discrimination Learning: Role of Working Memory. Plos ONE,11(1), 1-18. doi:10.1371/journal.pone.0147320
10. Maehler, C. m., &Schuchardt, K. s. (2016). The importance of working memory for school achievement in primary school children with intellectual or learning disabilities. Research In Developmental Disabilities, 581-8. doi:10.1016/j.ridd.2016.08.007
11. Ribeiro Silva, M., da Silva, C. C., da Fonseca, L. R., & da Silva, L. C. (2016). THE TRANSACTIVE MEMORY SYSTEM AND GROUP LEARNING.Revista De Administração FACES Journal, 15(2), 47-65.
12. NANDHINI, M., & SIVANANDAM, S. N. (2015). An improved predictive association rule based classifier using gain ratio and T-test for health care data diagnosis. Sadhana, 40(6), 1683-1699.
13. Wang, M., & Liu, G. (2016). A Simple Two-Sample Bayesian t -Test for Hypothesis Testing. American Statistician, 70(2), 195-201. doi:10.1080/00031305.2015.1093027
14. Kreinovich, V., &Servin, C. (2015). How to Test Hypotheses When Exact Values Are Replaced by Intervals to Protect Privacy: Case of t-tests.International Journal Of Intelligent Technologies & Applied Statistics, 8(2), 93-102. doi:10.6148/IJITAS.2015.0802.01
15. AQUILONIUS, B. b., & BRENNER, M. b. (2015). STUDENTS' REASONING ABOUT p-VALUES. Statistics Education Research Journal, 14(2), 7-27.
|
| 网站地图 |


